
| Home | Products | Consulting Services | Contact us |
NMRPredict:
| Modgraph Home | ||
| NMRPredict Overview | ||
| Carbon 13 NMR Prediction | ||
| Proton NMR Prediction | ||
| Try NMRPredict | ||
| NMRPredict and Mestrelab Research | ||
| Pricing |
NMRBenefit
How to optimize structural diversity during database building with respect to your chemistry.
NMRBenefit is one of the most major developments in NMR prediction and databases in the last 20 years.
It can now be used to help with the building of both carbon and proton user databases.
A major article on NMRBenefit was published in the February/March 2006 issue of Spectroscopy Europe which talked in detail about NMRBenefit. Click here to download the article.
The only way to get reliable, verifiable Carbon 13 and Proton NMR prediction is by using the HOSE code method of prediction which relies on a high quality underlying database. The problem with the HOSE code method is that very often, particularly with companies who are working on novel compounds, the query molecule is so unlike any record in the database that HOSE code prediction can only be made to 1 or 2 shells and is therefore wholly unreliable.
A typical example is shown in the screenshot below. Even when making a prediction against a carbon 13 database containing nearly 200,000 structures 15 of the 19 carbon atoms cannot be predicted reliably by the HOSE code method. There is simply no similar environment in the database.
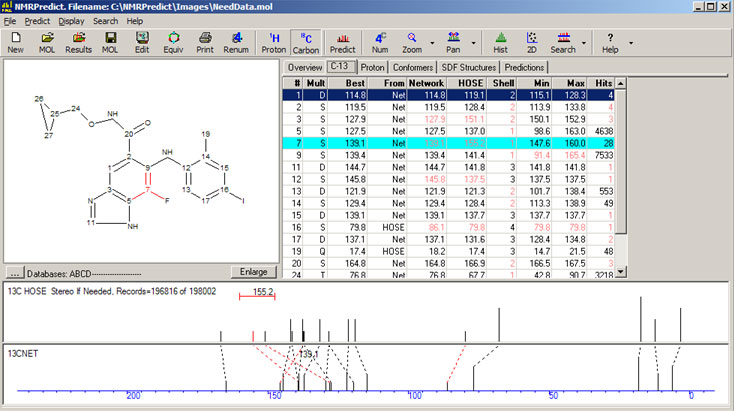
One solution is to use a Neural Network algorithm which is much more tolerant to molecules not previously seen by the database.
The best solution is undoubtedly to add your own related data. The problem then is that adding data is a very time consuming task. Many companies have thousands or even hundreds of thousands of records which they could add to their own database. However, they simply do not have the resources to add such vast quantities of data. Users are often aware that just adding a small percent of their available data would make a massive difference to the accuracy of their predictions - but which data do they add first?
NMRBenefit addresses this problem. Developed by Professor Wolfgang Robien, who has over 25 years experience is building databases for C13 NMR prediction, its process is simple:
- Install NMRPredict with its internal database of 258,670 Carbon data (444,177 including the Wiley data). Install the proton internal database which comes with NMRPredict if running Proton NMRBenefit.
- Put together an SD file containing the chemical structures which you may want to add to your internal prediction database. Please note that all you need is a standard SD file - you do not need any NMR data or assignments at this point
- Run NMRBenefit which will make a comparison of the internal database compared to the SD file. Depending on the size of the SD file this process could take several hours. A rough estimate is that NMRBenefit will be able to process about 3,000 structures per hour
- At the end of the NMRBenefit process a report is generated saying which of your data should be added first to an internal prediction database, and in what order, to get the most benefit
A typical summary after running NMRBenefit would look like this:
Before using NMRBenefit all of your 231 compounds could be predicted at level 1
You need to add:
10 of your 231 compounds (4.33%) to always achieve level 2
26 of your 231 compounds (11.26%) to always achieve level 3
43 of your 231 compounds (18.61%) to always achieve level 4
62 of your 231 compounds (26.84%) to always achieve level 5
When you purchase a full copy of NMRBenefit you will receive a full detailed output, which lists exactly which of your structures need to be added - and in which order, to be of the most benefit to your organisation.